
データサイエンティストとして働くのであれば、データサイエンス力は必要となってきます。
しかし、データサイエンス力と言われても、具体的にどういったスキルがデータサイエンス力に該当するのかを知らないと言う人も多いかと思います。
ですので、今回は、データサイエンティスト協会が出しているスキルチェックリスト(スキルチェックシートリンク)を参考に、データサイエンティストに必要なデータサイエンス力を20項目紹介していきたいと思います。
データサイエンスをテックアカデミーで学ぶ
週2回マンツーマンでのメンタリング、毎日15〜23時のチャット・レビューサポートで短期間でPythonを使って様々なモデルを構築し、データ分析を行うプログラム。
統計学の基礎やPythonで実際に分析する方法まで習得することができます。
※条件を満たすことで受講のために支払う受講料の最大70%が教育訓練給付金としてハローワークから支給されます。(詳細はリンク先で確認。)
目次
基礎数学
基礎数学とは、統計学や線形代数学、微分積分学のことを指します。
大学の1,2回生で学ぶ数学の範囲ですね。
この中でも特に重要なのが統計学です。
統計学は、何かデータから知見を得るためにデータサイエンティストが用いることの多い学問です。
簡単なところで言うと、平均値や最頻値などを求めるといったことも統計学ですし、発展した内容で言うと、ベイズを用いた推論や、統計的検定なども根底に流れているものは統計学です。
統計学は、データサイエンティストの基礎といってもいい学問なので、まず身につけることをお勧めします。
以下の記事で、詳しく勉強方法を解説していますので、興味のある方はぜひ読んでみてください。
線形代数学や微分積分学なども機械学習を理解する上では必要になってきますが、研究レベルで機械学習に関わるような場合でなければ、優先順位の高い学問ではありません。
線形代数学や微分積分学は、もちろん必要ですが、余裕が出てきたときに学ぶと言う方針でも良いでしょう。
予測
予測とは、その名の通り、現実世界により近い予測モデルを作成するためのスキルです。
予測は学習と評価のステップに大きく分類されます。
学習
まず、一つ目の学習に対しては、以下の三つを正しく設計する必要があります。
学習に必要な項目
- 目的変数
- 説明変数
- 予測モデル
一つ目の目的変数とは、予測したいもののことです。
例えば、飲食店の売上を予測したければ、飲食店の売上が目的変数になります。
では、目的変数ってそんなに真剣に考える必要がないのではないかと考えがちですが、そうでもありません。
目的変数の取り方によって予測の難易度が変わってくるとこともたくさんあります。
代表的なものが株価予測です。
純粋に考えると、株価をそのまま目的変数にすれば良いと考えてしまいますが、こちらは上手くいきません。
株価を予測するときは、株価がある地点より上がるか下がるかと言う目的変数を置くと予測ができるようになります。
株価を予測したい目的は、株価自体が知りたいのではなく、そこに投資したときにどれだけのリターンが得られるかを知りたいと言うことなので、後者の予測でも良いですよね。
このように、真の目的とは何なのかを正確に考えて、その目的に合わせて予測できるものを目的変数に選ぶスキルはとても重要です。
二つ目の説明変数とは、目的変数を予測するために使う特徴量のことです。
株価予測で言うと、前日の価格であったり、取引量であったりといったものですね。
こちらを考える際はいかにビジネス的な知見があるかと言うことが大事です。
株価を予測する特徴量を作るのは、プロのデータサイエンティストよりも、株のトレーダーの方が精度が良かったりします。
その分野に精通していない場合は、精通した人に質問して特徴量を作っていくのが良いでしょう。
三つ目の予測モデルとは、予測に使用するモデルのことです。
説明変数と目的変数が決まればそれに合わせた予測モデルを選ぶ必要があります。
例えば、説明変数が画像の場合はCNNを使うかもしれませんし、説明変数が株価の時系列の場合はRNNを使うかもしれません。
このように説明変数と目的変数によって適切なモデルを選ぶ必要があります。
評価
次に評価の部分について、説明していこうと思います。
評価については、主に以下の2点を考える必要があります。
評価に必要な項目
- 評価指標
- 評価データ
一つ目の評価指標は、予測の精度を図るための指標のことです。
予測の精度を測るための指標は、AUCやMAP、MSEなど実に様々なものがあります。
そのため、予測したいものに対して、この評価指標を適切に決めていく必要があります。
二つ目の評価データは、モデルを評価するデータのことです。
モデルを正しく評価するためには、現実に存在しない特定のバイアスが乗ったデータであってはいけません。
この特定のバイアスを乗らせないと言うのが、データによっては難しいのですが、できるだけ実運用の環境に近づけるために、評価データは訓練データより、未来のものを使ったり、評価データを複数に分けるクロスバリデーションを行なったりする必要があります。
検定・判断
検定・判断とは、統計的検定を行いその結果を正しく判断できるスキルです。
この統計的検定は、作成したモデルが正しく機能することをテストするために行うことが多いです。
そのため、この統計的検定を間違った方法で行う、またはその結果を元にした判断を間違ってしまうと、正しく機能していないモデルをリリースしてしまうことに繋がります。
そのため、この統計的検定を正しく行うことは事業がおかしな方向に進んでいかないようにするためにとても重要なことであると言えるでしょう。
グルーピング
グルーピングとは、教師なし機械学習においてデータを特定のグループに分けるスキルです。
このグルーピングは主に顧客のセグメント分析やシステムの異常検知などで用いられることが多いです。
教師なし機械学習のグルーピングは、階層クラスター分析と非階層クラスタ分析に分かれます。
階層クラスタ分析は、似ているデータを一つずつ順番にグルーピングしていく手法です。
この似ていると言う部分を表す指標を変えることで、結果が変わり、群平均法、ward法、最長一致法など様々な手法が存在します。
非階層クラスタ分析は、グループ数を最初に決定し、そのグループ数だけの代表点を抽出し、各データがどの代表点のグループに近いかでグルーピングしていく手法です。
代表的な手法としては、k-means法が挙げられます。
性質・関係性の把握
性質・関係性の把握とは、その名の通り、単データの性質、複数データの関係性を把握するスキルのことです。
性質・関係性の把握は、仮説を立てる上でとても大切です。
実際にデータを図にすることで、いろんな発想が湧いてきます。
精度の良い仮説を立てるため、また、その仮説を納得してもらうために、性質・関係性の把握は必須です。
単データの性質の把握とは、一変数のデータを把握することです。
よく行うのは、ヒストグラムを書いて、変数の分布を見ると言うことです。
特に目的変数となる変数に関しては、分布を見て、手法を決めると言うことをします。
複数データの関係性の把握とは、二変数以上のデータの関係性を把握することです。
散布図を書いて関係性を見ることであったり、変数間の因果を考えることなんかもこの複数データの関係の把握に含まれます。
特に因果を考えるのは、因果推論という分野が確立されているぐらい奥が深いことなので、ここを極められると、世の中を正しく理解するのに役立つと思います。
サンプリング
サンプリングとは、調査を精度よく行うために、母集団から選択する標本を決めるためのスキルである。
調査を行う際に、母集団からどういった標本を抜き出すのかは、とても重要です。
標本を決める際に必要となってくるのが以下の2点です。
標本決定に必要な項目
- 標本抽出
- サンプルサイズ
標本抽出
一つ目の標本抽出とは、母集団の中から標本を抽出することです。
例えば、全小学生の男女の身長差を調査したい場合を考えましょう。
世界の小学生を全て調査すれば、母集団の特性は把握できますが、これはコストが膨大にかかるため、今回は特定の学校をいくつか抽出して、その特性を世界の小学生の特性としたいとします。
このときに、どういった小学校を抽出し、どういったように生徒を選んでいくかと言うことを決めていくのが、標本抽出です。
もし、男子は全て小学六年生から、女子は全て小学一年生から選ぶと、身長差は母集団よりも大きくなるでしょう。
もし、ある国の小学生だけを対象として、選ぶと、身長差が母集団の傾向と離れていたと言うことも考えられるでしょう。
このように選び方によって、標本にバイアスがかかってくるため、このバイアスがほとんどないように標本を抽出する必要があります。
この抽出方法には、層化抽出法、クラスター抽出法、多段階抽出法など様々なものがありますので、興味のある方は調べてみてください。
サンプルサイズ
二つ目のサンプルサイズとは、標本を抽出する数のことです。
サンプルサイズは、大きすぎると検証のコストがかかってしまいますし、小さすぎると結果を正しく認識することができません。
そのため、適切なサンプルサイズを設計する必要があります。
詳しくは以下記事で解説しておりますので、参考にしてください。
データ加工
データ加工とは、使用する分析手法に使用する変数を手元にあるデータの適切な加工により作成するスキルです。
データ加工には、データクレンジングと特徴量エンジニアリングの二種類が存在し、それぞれデータ加工の守りと攻めを担当しています。
この二つについて説明していきます。
データクレンジング
データクレンジングとは、用いる手法が適切に動作するために変数を作成するスキルです。
データ加工の守りの技術ですね。
このデータクレンジングを行わないと、そもそも手法が動作しないこともあるため、必ず知っておくべき内容です。
例えば、ニューラルネットに入力する際に全てのデータの尺度を統一するために、標準化するなどが挙げられます。
また、欠損値を埋めたり、異常値や外れ値を除外したりと言ったものも、このデータクレンジングです。
特徴量エンジニアリング
特徴量エンジニアリングとは、手法の精度を上げるために変数を作成、加工するスキルです。
データ加工の攻めの技術となります。
機械学習エンジニアリングの80%以上は特徴量エンジニアリングと言われているぐらい、この特徴量エンジニアリングのセンスによって、手法の精度は大きく変わってきます。
特徴量エンジニアリングをうまく行うためには、エンジニアリング技術とドメイン知識の両方が必要です。
前者のエンジニアリング技術とは、特殊なデータに対して、よく行われる加工のことです。
例えば、季節特徴量には三角関数を使用するや、時系列データは移動平均を使用するなどが挙げられます。
後者のドメイン知識とは、その分野の知識ということです。
もし、株価を予測するモデルを作るとなった場合は、株に詳しい人が見ている指標にはどう言ったものがあるのか、そしてなんでその指標を見ているのかと言ったことを知っている必要があります。
この特徴量エンジニアリングは、経験によって学ぶことが多いため、データ分析コンペなどに参加してみて、学んでみるのが良いかと思います。
以下の記事でおすすめのデータ分析コンペを紹介していますので、興味のある方は是非みてみてください。
データ可視化
データ可視化は、大量のデータを分析しやすいように視覚化するスキルのことです。
このデータ可視化は、皆さんもよく行っているのではないでしょうか?
エクセルで棒グラフや円グラフなどを作成することは、まさにデータ可視化です。
イメージしやすいですよね。
しかし、このデータ可視化は実は奥が深いです。
軸をどう定義するか、大量のデータから使用するデータをどう決めるか、どう言ったツールを使用して可視化を行うか、どのグラフを使うか、などなど考えることはたくさんあります。
こちらのデータ可視化を本気で学びたいのであれば、一回体系的に学ぶのが良いでしょう。
データ可視化を学びたいのであれば、個人的に以下の本がおすすめなので、興味のある方はぜひみてみてください。

分析プロセス
分析プロセスとは、明確化された課題が渡されたときに、適切な手法を選択し、解決までの道筋を立てるスキルです。
そりゃ必要だよねと言うスキルですね。
このスキルを身につけるためには、このページで説明されているデータサイエンス力スキルに対して、メリットとデメリットを整理する必要があります。
どう言う条件でうまくいき、どう言う条件でうまくいかないのかと言うことを把握しておくことが必要です。
また、可能であれば、自分で実際に手を動かしてみて、感覚値として、うまくいくかいかないかを理解できるとなお良いでしょう。
データの理解・検証
データの理解・検証とは、データの特徴的な部分を理解し、集計された結果が正しいものかを確認するスキルのことです。
今回は、データの理解とデータの検証の二項目に分けて説明していきます。
データの理解
データの理解は、データの種類、作られ方、関係性などを理解し、そこから適切な集計を設計することです。
最終的なゴールとしては、データは利用できる状況と利用できない状況などをER図やテーブル定義書から瞬時に理解でき、目的に合わせた集計を設計できるようになることです。
このデータ理解には、データベース構造を学ぶことが必要になります。
データベースの主キーは何なのか?テーブル同士の関係性はどうなっているのか?を日々の業務の中で意識しながら作業をしていると身についていきます。
データベースの構造なんて意識したことないよと言う人は、データベースの設計を一からやってみることをお勧めします。
データ検証
データの検証は、集計されたデータが正しいかどうかを判断することです。
集計には、ミスがつきものです。
そして、そのミスに気づかないまま、一度受け入れてしまうと、その後ミスに後から気づくことはとても難しいです。
そのため、集計が正しく行われているのかを、コード面、定性面の両方から検証する必要があります。
まず、コード面ですがこれは言うまでも無く正しいコードが実行されているかと言う部分です。
もし、コードでは無く、何かのツールを使用して集計をしていると言うことであれば、そのツールの使い方を間違えていないかと言う部分を見てあげてください。
次に、定性面ですが、これは集計結果が自分の感覚値と合うかと言う部分です。
感覚値と合わない場合、新しい発見をしたと喜んではいけません。
こう言った場合は、集計が間違っていることがよくあります。
間違った部分がないかを念入りに調査して、感覚的に理解できるような仮説を立て、検証することが大事です。
そして、念入りな精査の結果、それでも集計結果があっていた場合は、その結果は大発見です。
このように、感覚値と合わない場合は、間違いを探すと言う姿勢が大事です。
意味合いの抽出・洞察
意味合いの抽出・洞察は、分析結果をその手法の特性を理解した上で考察するスキルです。
可視化や、予測を行う際に、その手法の特性を理解することはとても重要です。
特に、その手法の結果が想定と違った場合に、手法の特性を理解していないと、深い考察をすることができません。
自己の仮説が間違っていたのか、それとも仮説はあっていたが手法が間違っていたのかを見極めるために、この手法の特性を深く理解し、意味合いの抽出・洞察のスキルを高めてください。
機械学習技法
機械学習技法とは、機械学習を使用するためのスキルです。
データサイエンティストといえば、と言う技術ですよね。
機械学習は、大きく分けて、教師あり機械学習、教師なし機械学習、強化学習の三種類があります。
3種類の機械学習それぞれに対して、無数の技術が存在するため、それを一個一個学んでいきながら、地道に身につけていく必要があります。
こちらの項目は細かく説明し出すととても長くなるため、本記事では解説しませんが、勉強したいと言う方は、以下の記事に機械学習の勉強方法をまとめていますので参考にしてみてください。
時系列分析
時系列分析とは、その名の通り時系列のデータを分析するスキルです。
時系列データとは、データに時間の要素を持っているデータのことです。
株価などを想像してもらえるとわかりやすいかと思います。
時系列分析に対して、特徴量作成とモデル作成の観点で解説していきます。
まず、特徴量作成に関しては、時系列データは通常のデータに加えて、以下の二つの特徴を持っております。
時系列データ特有の特徴
- トレンド
- 周期性
トレンドとは、ある出来事に起因する変化のことです。
株価で考えるとコロナによって株価が下がったみたいなものがトレンドです。
このトレンドの期間は出来事の大きさによって、変わってきますが、どのトレンドにも共通して言えることは、一定期間はその変化が起こり続けると言うことです。
そのため、このトレンドを捉えることはとても重要になってきます。
次に周期性とは、定期的に起こる変化のことです。
株価で考えると毎年8月は株価が下がりがちみたいなことです。
定期的に起こるため、未来の予測に対しても同じ現象が起こることが考えられます。
そのため、周期性を捉えることは重要になってきます。
次に、モデル作成について説明させていただきます。
モデルに関しては、一般的なモデルに加えて、LSTMと言う時系列予測をするためのニューラルネットワークが使用されることがよくあります。
このLSTMは、ある地点の入力だけではなく、過去の地点の入力も参考にするモデルであり、時系列予測において相性がいいため使用されます。
時系列予測に興味のある人はぜひ知っておきたい手法ではあります。
言語処理
言語処理とは、文字列に対して分析を行うスキルのことです。
例えば、SNSの文章からその人の感情を予測するなどが挙げられます。
この言語処理に対しても、特徴量作成とモデル作成の観点で説明していこうと思います。
特徴量作成は、言語処理においてはとても大切な技術です。
機械学習の入力には、基本的には文字を直接使用することはできません。
そのため、言語を数値のデータに変換する必要があります。
また、文章を特徴量とする場合、文章によって文字数が違うものを同じ次元のデータに変換する必要もあります。
このように文字列を同次元の数値特徴量に変換するためには、様々な考慮すべきことがあります。
今回は詳しく説明しませんが、この技術は、形態素解析や、係り受け解析、名寄せ、構文解析など多くの技術があります。
モデル作成は、RNNやLSTMなどの他の手法でも使用されるものから、GPTやBERTなどの自然言語処理でよく見かける手法など様々なものが存在します。
基本的にニューラルネットの機械学習手法を使うことが多いです。
言語を分析するデータサイエンティストになりたい場合は、学んでみても良いと思います。
画像・動画処理
画像・動画処理とは、その名の通り、画像、動画データに対して分析をするスキルのことです。
例えば、App Storeにプリペイドカードでチャージする際に、プリペイドカードをスマホのカメラでとると自動的に文字を認識してくれる機能などが挙げられます。
この画像・動画処理に対しても、特徴量作成とモデル作成の観点で説明していきます。
まず、特徴量作成について説明します。
画像・動画処理では、言語処理と同様に数値のデータを作成する必要があります。
言語と違う部分は、画像や動画は予め機械学習の入力となりゆるデータにデジタル化されてPC上に保存されている点です。
そのため、このデジタル化されたデータがどう言う意味を持つのかを理解すれば、特徴量作成は簡単に行えます。
データを抽出した後は、リサイズ、パディング、標準化などの技術がありますが、これも画像とはどう言ったデータであるのかを理解していれば、簡単に理解できると思うので、まずは画像を理解するところから始めるのが良いかと思います。
次にモデル作成について説明します。
画像処理では、ほとんどCNNと呼ばれるニューラルネットワークを学習に使用します。
画像は、二次元の情報であるため、どこにどう言った情報があるのかと言うことも大事になります。
このCNNは、畳み込みの技術を使用して、画像の情報の位置関係も学習してくれるため、画像処理では必ずと言っていいほど使われています。
画像処理を行う場合はこのCNNをマスターし、その派生技術を学んでいくと言った流れにするのが良いでしょう。
音声/音楽処理
音声/音楽処理も、その名の通り、音声に対して分析をするスキルのことです。
音声認識や本人認証、感情分析など様々な分野があります。
その中でも一般的な音声認識を例に解説していこうと思います。
音声認識とは、人の声から何を言ったのかを理解する技術です。
AmazonのアレクサやiPhoneのSiriなんかを想像するとわかりやすいのではないでしょうか。
音声認識には以下の4ステップがあります。
音声認識の4ステップ
- 音響分析
- 音響モデル
- 発音辞書
- 言語モデル
音響分析とは、簡単にいえば特徴量を作成する技術です。
人の声の周波数のデータから機械が認識しやすい数値の特徴量を作成します。
ここら辺は、他の技術と同じですね。
次に音響モデルとは、この特徴量から言語の最小単位である、母音、子音、撥音の音素を特定するモデルのことです。
「おはよう」であれば、O,H,A,Y,O,Uという風に音素を特定します。
次に発音辞書とは、先ほど特定した音素を存在する言葉に変換する辞書のことです。
先ほどの音響モデルも100%の精度で音素を特定できるわけではないため、一定数誤りが出てくることがあります。
例えば、先ほどのおはようでいうと、「よ」を「いお」と認識し間違えて、O,H,A,I,O,Uと認識してしまうかもしれません。
その結果「おはいおう」という言葉が検知されるのですが、これは一般的に使われる言葉ではないため、明らかに不自然です。
こう言ったおかしな単語をきちんとした「おはよう」という単語に戻すのが、発音辞書です。
最後に、言語モデルとは、文章の並びを考慮して、言語を組み立てるモデルのことです。
これは、単語の後に出現しやすい単語のパターンを考慮することでより正しい文章として認識する技術です。
例えば、さっきのおはようも、アメリカの話をしている文脈では、「オハイオ州」のオハイオと言っていたかもしれません。
このように、文脈を考慮することでより正しい音声認識が可能となってきます。
音声認識はいくつもの工程が必要なため、決して簡単な技術ではないですが、これから対話式のロボットなどが普及していくだろうという未来を考えれば、学んでおいても良い技術かなとは思います。
パターン発見
パターン発見とは、あるデータ集合の中に現れるパターンを発見するスキルです。
これはレコメンドシステムなどでよく使われます。
例えば、amazonを使っていると、おすすめの商品などが出てきますよね。
このおすすめの商品は、カスタマーが過去買った商品の集合からカスタマーが買う商品のパターンを発見し、そのパターンに基づいてレコメンドがなされています。
具体的な手法としては、協調フィルタリングやコンテンツベースフィルタリング、Factrization Machineなどがあります。
カスタマー向けのサービスを行なっている会社では、よく使われる手法だと思いますので、勉強する価値はあるかと思います。
グラフィカルモデル
グラフィカルモデルとは、確率変数間の依存関係をグラフ表現したものです。
グラフと言っても、棒グラフや円グラフなどの一般的なグラフではなく、グラフ理論で使われる以下の図のようなグラフになります。
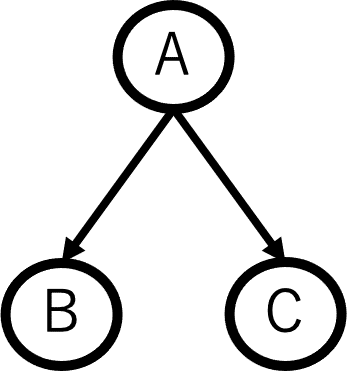
上記の図では確率変数がA,B,Cで表されており、Aが原因でB、Cが起きると言う関係を表しています。
今回は説明のため3変数のみが出てきた図になっていますが、実際はもっとたくさんの変数が出てきて複雑な図になります。
このグラフィカルモデルのいいところは、モデルを構築し事後確率を求めることで、目的として知りたい変数に対して、他の変数がどの程度影響を及ぼしているのかを知ることができるところです。
変数間の因果を知りたい場合、このグラフィカルモデルを使ってみるのも一つの手だと思います。
シミュレーション/データ同化
シミュレーション/データ同化とは、現実の事象をあるモデルを使って再現し、それをできるだけ現実の事象に近づけるスキルです。
イメージのしづらい方は、天気予報で出てくる天気図を想像していただけるとわかりやすいかと思います。
天気図は、将来の大気の状態を現在の観測値を元に、あるモデルに従ってシミュレーションして作成されています。
シミュレーションを行うにあたって、必要となってくるのが以下の三つです。
シミュレーションに必要な項目
- モデルの方法
- モデルの条件
- データ同化
まず必要となるのが、どうシミュレーションをしていくのかと言う方法です。
このシミュレーション方法には、モンテカルロ、ヒストリカル、agentベースなど様々なものが存在します。
次に大事なのがモデルの条件です。
これは、初期条件、境界条件、パラメータなどが存在します。
シミュレーションは条件が少し違うだけで全く違う結果になることが多いため、このモデルの条件は正しく設定する必要があります(この正しく設定するが本当に難しいです。)。
最後の、データ同化とは、シミュレーションした結果を現実に観測されているものに近づけると言う作業です。
世の中の物理現象を全てモデルに組み込めているわけではないため、シミュレーションと現実とではどうしてもずれが生じてしまいます。
そのため、現実の観測値も考慮に入れることで、このズレを修正すると言うのがデータ同化です。
シミュレーションは、意外と行う機会があるスキルなので、気が向いたときにでも学ぶと良いと思います。
最適化
最適化とは、システム最適化という学問における技術を使うスキルです。
問題を正しく設定し、きちんと解くことができると、得られた答えは最適であるため、答えの精度が高いです。
ひたすらに数式を使うため、数学に明るくない人は避けがちな分野ですが、個人的には学んでおいて損のない分野だと感じております。
最適化の手法は最急降下法やラグランジュ未定乗数法、動的計画法など様々ありますが、今回は手法ではなく、最適化の概要を知ってもらうため、最適化の際に設定すべき以下の三要素について説明します。
最適化に必要な項目
- 変数
- 目的関数
- 制約
これをダイエットを例にとって、説明していきましょう。
近くのスーパーにある食材の中から食べるものを選んでダイエットをしていきたいという場面を想定します。
ただ、体調を崩したくないため、ある程度の栄養素は取得したいとします。
結論から言うと、これは、食材の数を変数とし、金額と栄養素の制約のある、カロリーを最小化する最適化問題と言い換えることができます。
まず、変数とは変えられるものです。
この時の変数とは、それぞれの食材を買う数です。
人参を何個買うのか?肉を何g買うのか?そう言ったものが全て変数となります。
今回では、食材Aと食材Bだけに絞りそれがそれぞれ$x_1$個と$x_2$個あるとします。
次に、目的関数とは、最小化または最大化したい値を、変数を用いて表した関数です。
今回はカロリーを最小化したいため、食材Aが100kcalで食材Bが200kcalの場合、
$$100x_1 + 200x_2$$
となります。
最後に制約とは、変数が満たさないといけない条件のことです。
例えばタンパク質を60g以上とりたいとします。
食材Aが10gで食材Bが15gのタンパク質を含んでいた場合、制約条件は、
$$10x_1 + 15x_2 >= 60$$
となります。
この変数と目的変数と制約が決定すれば、後はそれに合う最適化手法を選んで計算するだけです。
今回の問題はとても簡単ですが、現実問題では式はとても複雑になっております。
そのため、どう言った問題に対して、どう言った解決法を適応するのか。
これを考えるのが大事であり、それが最適化のスキルです。
まとめ
今回は、データサイエンティストが身につけたいデータサイエンス力を20個紹介させていただきました。
長い記事にも関わらず、ここまで見ていただいた方は、データサイエンティストとして、本気で勉強したいと言う人だと思います。
全部を一気に学ぶのは難しいですが、一個ずつ着実に勉強していきましょう。
私のブログでも、そう言ったデータサイエンスを本気で学びたい人に向けて、これからも発信を行なっていきますので、参考にして学んで行ってもらえれば幸いです。
他にもデータサイエンティスト関係の記事もあるので、もっと知りたいという方は参考にしてください。
-


-
【知っておきたい】データサイエンティストに必要なスキルとは?
未経験くんデータサイエンティストになりたいんだけどどういうスキルが必要なの? 初心者くんデータサイエンティストとして、スキル磨いていきたいんだけど、どんなスキルを磨けばいいか分からない こんな悩みの人 ...
続きを見る
-

-
【受講料が70%OFF】AI人材のスキルをつけるオススメのAI人材育成講座を現役エンジニアが解説
★この記事は5分で読み終えることができます。現役エンジニアである筆者がAI人材のスキルを身に付けたい人に向けた解説記事になります。政府の補助を受けて70%の受講料が返還される制度について解説しています ...
続きを見る