
★この記事は10分で読み終えることができます。
現役エンジニアである筆者がGCPの VisionAPIを使ってテキスト抽出の方法を解説しています。
今回は、GCP(Google Cloud Platform)のVision APIを使って画像からテキストを抽出してみましょう!
本記事ではPythonを利用しています。サンプルコードもあるのでサクッと10分ほどでコピペして画像からテキスト抽出できると思います!!
目次
Vision APIを使って10分で画像からテキスト抽出
今回はこの平家物語の冒頭をGCPのVisionAPIでテキスト抽出していこうと思います!

あと、GCPを理解するのに参考になった本を載せておきますね。参考書探していた人は是非!!

Vision APIとは?
VisionAPIとは、Googleが一般ユーザに向けて提供している画像認識APIのことです。
APIを使うメリットは、機械学習でコストの大きいモデル学習の部分を我々が行う必要がないことです。
ただ逆を言うと、Googleが学習したモデルを利用することになるので予測の精度や日本語への対応なども全てGoogleに依存することになります。
とはいえ、現状でも日本語の認識精度は飛躍的に向上しており、VisionAPIを使って会議のホワイトボードの文字起こしするなんてことも可能になってきています!!
テキスト抽出してみよう
プロジェクトの作成
ではプロジェクトの作成をしましょう!!(もうしてる人は飛ばしてね!!)
下の画像のプロジェクトの選択というボタンをクリックして、自分で好きなプロジェクト名をつけてあげましょう〜!!

サービスアカウントの取得
これはGoogle Cloud Platformのサービスを使用する為に取得しなければならない認証キーです。
以下のようにサービスアカウントをjson形式のファイルで作成します!!
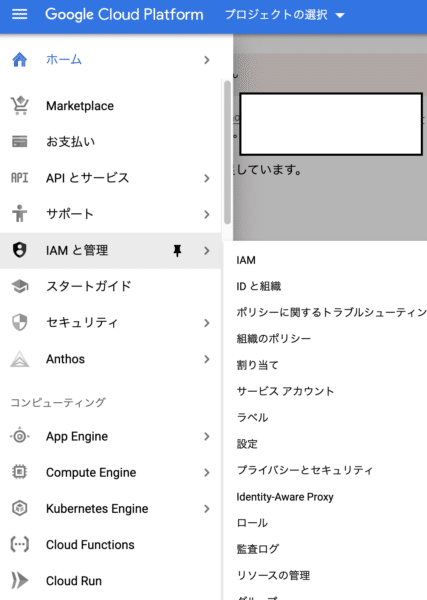
1. 左上のボタンから「IAMと管理」>>「サービスアカウント」を選択
2. サービスアカウントの作成を選択してjsonファイルをダウンロード
Cloud Shellの起動
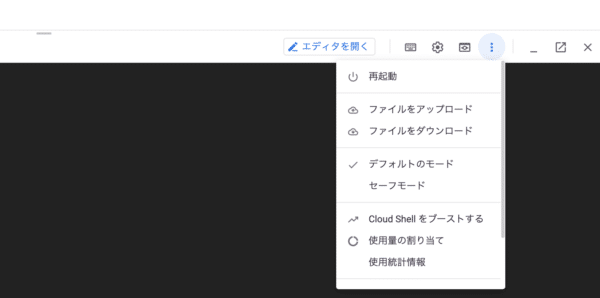
Cloud Shellを起動するためには、GCPの画面の右上にあるShellボタンを押します。
下の画像の左から二番目のボタンです。
Shellを起動してサービスアカウントのjsonファイルを「ファイルのアップロード」でアップロードしてください(下の画像参照)
pythonのサンプルコード
続いて必要なpythonファイルを作成しましょう!!
下のコードをコピーしてpythonファイルを作成し、先ほどのようにpythonファイルをアップロードしましょう。
このコードは「document_text_detection」という画像に対して認識した文章を返してくれる機能です!便利!
「document_text_detection」を「label_detection」とすると画像のオブジェクト認識ができたり、「text_detection」とすると抽出した単語を返してくれます!!!
同じように、テキスト抽出したい画像をアップロードして、「hoge.jpg」の部分に画像の名前を入れてくださいね
# 画像1枚をテキスト抽出にかけるプログラムです
from pathlib import Path
from google.cloud import vision
import os
# 画像のパスを指定してあげます
p = Path(__file__).parent / "heike_story.jpg"
# インスタンス作成
client = vision.ImageAnnotatorClient()
# 画像ファイルを読み込む
with p.open('rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# Vision APIのライブラリ指定
response = client.document_text_detection(
image=image,
image_context={'language_hints': ['ja']} # この引数で日本語の認識してほしいと指定
)
document = response.full_text_annotation.text
# 結果取得
print(document)【最速で学ぶ - Google Cloud Platform(GCP)入門完全攻略コース】
GCPを学ぶためにオススメのUdemy講座です。筆者も体系的な知識をつけるのに役立ちました。
講座の最初は無料で受けられるので、雰囲気だけでもみてみてください!
画像認識を実行してみよう!
まず、サービスアカウントキーを使って自分を認証してあげます。
Shellに下のコマンドを打ち込みましょう!!
export GOOGLE_APPLICATION_CREDENTIALS="取得したjson名.json"これでVisioAPIが利用できるようになりました。
今いるディレクトリにサービスアカウントのjson、python、jpgがあればOKです。
では、pythonを実行しましょう
python doc_detection.pyすると、下のように文章が返ってきました!
少し間違っていますが笑。。。悪くない精度ですね

私が参考になったUdemyの講座を載せておきます。GCP利用したい人にはおすすめです。
【現役エンジニアが教える、手を動かして学ぶGoogle Cloud Platform(GCP) 入門】
まとめ
VisionAPIによるテキスト抽出はいかがだったでしょうか??
10分程度でGoogleのサービスを利用して画像のテキスト抽出ができてしまいました!
GCPには他にも数多くのサービス・機能があるので、今後もGCPについてまた紹介記事を書いていこうと思います!!
読んでいただきありがとうございました!