
★本記事はサンプルコード付きでコード一つ一つ丁寧に解説をしています。
★扱うプログラミング言語はPythonです。
今回Webスクレイピングする対象のWebサイトは「天神橋筋商店街」です。
![もう迷わない】天神橋筋商店街のおすすめグルメならココ!20選をご紹介! - SPIRA [スピラ]](https://spi-ra.jp/wp-content/uploads/2019/12/45150994_m-1080x720.jpg)
天神橋筋商店街は、日本一長い商店街として有名です。商店街のお店一覧から店名データを取得してみます。
PythonでWebスクレイピング
必要なライブラリをインストール
では、必要なライブラリをインストールします。
ターミナルを開き
今回はpipでインストールします。
pip install beautifulsoup4 requests pandas【コード解説】
- 「beautifulsoup」はスクレイピングに必要なHTMLをパース(プログラミングで解析できる形に変換すること)するためのライブラリです。
- HTMLを「request」というライブラリで取得し、「beautifulsoup」で扱える形に変換するということですね。
- そして「pandas」はデータ解析用ライブラリです。pandasは利用しませんが使えるようにと書いてあります。
店名データをHTMLで確認
取得したい情報を選ぶ
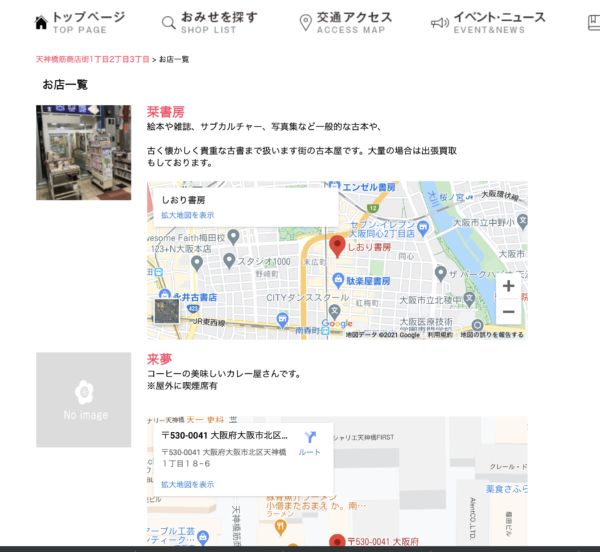
商店街のお店一覧ページの1ページ目に掲載されているお店の名前を取得してみます。
下記の画像の「栞書房」や「来夢」などの店名です。
HTMLで確認
取得したい対象のオブジェクトがHTMLでどのように記述されているかを確認します。
h1タグで記述されていたらh1を指定することで店名がとってこれるという寸法ですね。
まず、サイト上で[右クリック]をして、[検証]を選びます。(下の画像参照)
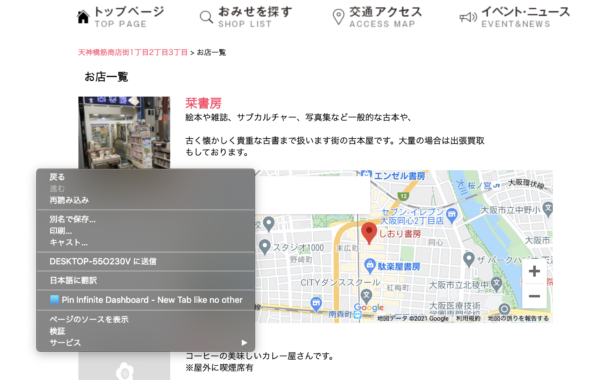
すると下のような検証用ツールが出てくると思います。
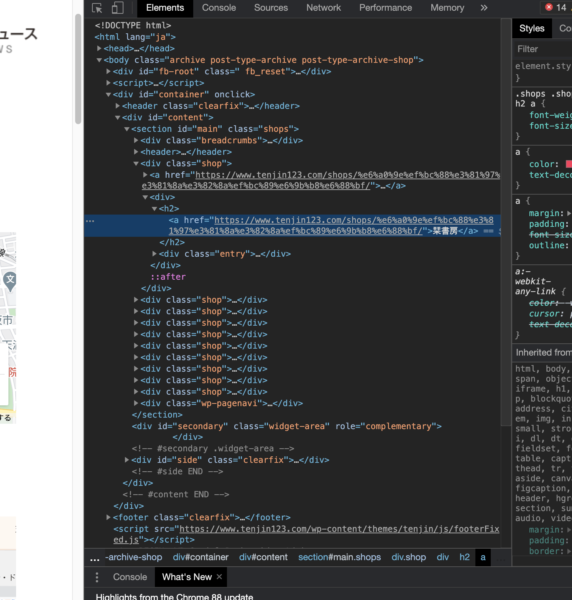
検証用ツールの[Elements]をぽちぽち押していくと、下の画像のような店名にハイライトされる部分があります。
h2タグの中のaタグに記述されたテキストであることがわかります。
これで準備が整いました。
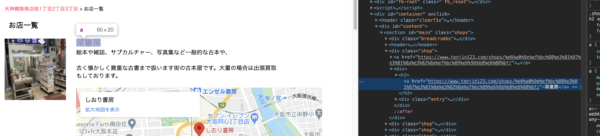
店名データの取得
ライブラリをインポート
ここからはPythonファイルで作っていきます。
""" 必要なライブラリのインポート """
import pandas as pd # 通例としてpdという名前をつけてあげます
import requests
from bs4 import BeautifulSoup店名データの取得
ではライブラリを利用して店名データを取得してみましょう。
# 対象のWebサイト
url = "https://www.tenjin123.com/shops"
# HTMLを取得
response = requests.get(url)
# 文字化け防止
response.encoding = response.apparent_encoding
# 解析できる形にパース
soup = BeautifulSoup(response.text, "html.parser")
# selectで取得したい店名を指定
shopname = soup.select("h2 a")
【コード解説】
最後の行まではおまじないみたいに定型文で覚えてもらって問題ありません。
最後 selectを使って店名が含ませる要素を取り出していますが、取り出し方は様々な方法があります。
今回はselectでh2タグの中のaタグなので "h2 a"と書いてあげます。
するとリスト型でaタグの一覧が取得できました。
shopname = soup.select("h2 a")
print(shopname)
# [<a href="https://www.tenjin123.com/shops/%e6%a0%9e%ef%bc%88%e3%81%97%e3%81%8a%e3%82%8a%ef%bc%89%e6%9b%b8%e6%88%bf/">栞書房</a>, <a hre...]あるタグの中のテキストを取り出すには、textメソッドを使います。
# あとはテキストを取り出す
# リストになっているので最初の要素から順番に取り出すようにループを作る
for shop in shopname:
print(shop.text)
"""
栞書房
来夢
きもの松葉 天神橋店
なに屋 南森町店
友茶YOUCHA天神店
株式会社 保険工房
茶千歳
ニッカブロックパーク天神橋店
串焼き居酒屋 結び。
一品居蘭州牛肉麺
"""店名が取得できました!
まとめ
今回は商店街の一覧ページから店名を取得しました。
同じようにどのようなページでも取得することができます。
ただ、著作権などの侵害にならないように取得したデータを商業利用する場合は気をつけてくださいね。