
Pythonというプログラミング言語は、データサイエンスに欠かせないプログラミング言語です。
データサイエンスとは、あるデータに対して何かしらの解析を行う事です。データには例えば年収や性別であったり車の交通量であったりします。それらのデータを使って、年収や性別から職業を予測したり、今日の車の交通量から明日の交通量を予測したりします。面白そうですね!
そして、データサイエンスをするにあたってPythonという言語が主流になるんですが、それにはいくつか理由がありますが大きな理由としてPandasと言うライブラリがある事と言えます。
Pandasについて本気で丁寧に説明しています。ぜひ読んでみてください!
Pandasの超基本講座
ライブラリとは?
まずはライブラリという言葉からですね。ライブラリと言うのは、プログラミング言語ごとに作られた便利な機能がまとまっているパッケージのことです。
例えば、救急箱のようなものです。救急箱を運動場に持って行っておくと、切り傷には消毒液、捻挫にはテーピングなど様々問題に対処する術がまとまってパッケージ化されてますよね!
ライブラリとはまさに救急箱です。Pandasと言うライブラリはデータサイエンスの様々な問題に対する術が詰まった素晴らしいものなのです。
インストールしてみよう
インストール方法を紹介しますね。インストールとは、使いたい機能をパソコンにダウンロードする事です。ではみていきましょう。
はじめにターミナルを開きましょう。Windowsなら「コマンドプロンプト」、Macなら「ターミナル」を開いてみてください。どちらも最初からパソコンに入っているので探してみてください。
開くと下の画像のような黒い画面が出てきます。
この黒い画面を通じてインストールしていきましょう。インストールするためにpipと言うインストーラーを使います。まずはそのpip自体が入っているかを確認します。
黒い画面に下のコマンドを入力してEnterキーを押してください
pip -V (-Vをする事でpipのversionを確認できるコマンドです)何かしら文章が出てくると思いますが、pipのバージョンの数字が表示されている人はpipが入っているので問題ありません。
バージョンが確認できない人は下のコマンドでpip自体を入れましょう。
sudo easy_install pipさて、pipがみなさん入ったと思いますので早速Pandasをインストールしてみましょうか。下のコマンドを入力してください
pip install pandasこれでインストールは完了です。実際にPandasを書いていきましょう!
簡単に実装できる
Pythonのインストールは済んでいることを前提としているので、Pythonが入ってない人はぜひこちらの記事を確認してみてください。
Pythonのインストール方法徹底解説!
ここからは実際にPandasに触れてみましょう!
Pandasと言うライブラリはデータサイエンスに適した救急箱のようなものだと言いました。実際にデータにおける処理はPandasでほとんどできてしまいます。
ここからはテキストエディターを使ってPythonを書いていきます。Pythonと言うプログラミング言語でPandasというライブラリが使えるためです。プログラムをどうやって書けばいいのかわからない人は丁寧に説明しているので参考にしてみてください!
【初心者必見】テキストエディターの使い方やプログラミングの書き方
Pythonのファイルを作成できた人はここから読み進めてください。
さて,まずはPandasのインポートをしないといけません。
インポートとは、パソコンにPandasは入っているけど入っているだけでは使えないので、プログラムを書くときに使いますよーってことを書いてあげる必要があります。
インポートしてあげましょう。Pythonファイルのはじめに以下のコードを書いてください。
import pandas as pdas pd の部分はこれ以降のコードを書くときに、いちいちpandasと書くのがめんどくさいのでpdと省略して書きますよっという意味です。
では具体的にpandasのできることをみていきましょう。基本的に扱うデータは2次元のデータになります。
よく出てくる簡単な用語から説明していきますね。
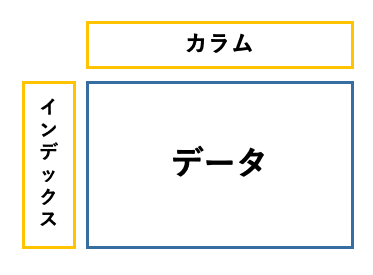
Pandasで扱う2次元データはデータフレームという名前で呼ばれています。そして上のような構造をしています。インデックス(index)は、よく日時や人物名が使われ、カラム(columns)には様々な要素が入ります。
例えば下のような感じになります。
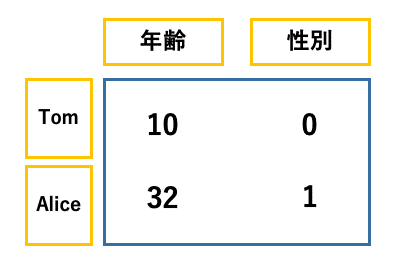
データフレームの中身はバリュー(values)と言います。Tomの年齢は10才であることはわかりますが、性別が0とはどういうことでしょう?これはデータを扱う際に必要な知識ですが、性別のような男と女のような数字で表されてないデータはたくさんあります。性別以外にも職業や住んでいる都道府県などは数字では表せませんよね。そのようなデータに対しては数字を割り当てる必要があります。
男には「0」女には「1」の数字を割り当ててあげます。
そうすれば0というデータを見れば男ということができますね!
このようにしてデータを扱いやすくしていきましょう。
ではデータをくっつけたり、切り分けたり、インデックスを変更したりする方法をみていきましょう!
次回の記事で具体的なサンプルコードを紹介いきます!!